One of the most difficult pages to scrape is the Google Search Result (SERP) pages. I have tried different modules such as Selenium, Requests, and Urllib, but creating a robust Google Search Result scraper is almost impossible. Therefore, I recommend you to use an API, such as Scale SERP. I have used other APIs such as Zenserp, SerApi and Serpstrack, but I have had the best experience with Scale SERP. In this article, you can read how to scrape Google Search Result Page using Python, what the advantages are of Scale Serp and why creating your own scraper is so difficult.
Why creating your own SERP scraper is so difficult
If you have tried scraping Google Search Result pages using Python before, you might have experienced how difficult it is. I think there are few main reasons why this is so hard:
- The HTML structure of the search result page makes it difficult to choose a good Xpath or CSS selector
- Class and ID names of the search result pages are updated regularly
- Google will make you fill in a ReCaptcha whenever you doing multiple searches
Difficult to find a good Xpath or CSS Selector
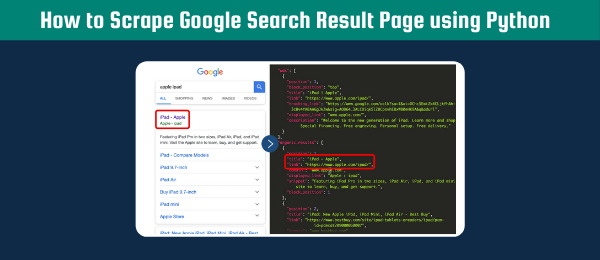
Whenever you are scraping, you are always looking at the HTML structure of a website. If you look at the HTML structure of the Google Search Result Page, you can see that the structure contains arbitrary names for classes and ids. In contrast, some websites have really useful names that allow you to easily select the element that you are interested in. For example, the element below would be easier to select if the class name would have been “serp_hyperlink”.

Right now your only option is to make use of the class name of the parent div element yuRUbf. You could for example use the following CSS selector: “.yuRUbf a”. However, you will automatically select other <a> elements that you are not interested in (see example below). Even if you try to go more specific with the following CSS selector: “.yuRUbf a:nth-child(1)” you will not get the results you want. Do not get me wrong, I am not saying it is impossible to find the right CSS selector, but I am just illustrating how difficult it can be for Google Search Result Page. At this moment we are only looking at hyperlinks within normal results. You can imagine that if you are interested in knowledge graphs, images, or shopping result pages it might get even more complicated.

Class and ID names are updated regularly
This is something I discovered because I wrote a small scraper a while back, and then I want to test it a few months later. Somehow my scraper did not work at all, and when looking at my selectors I found out that the class names had changed. Yes, I would be able to fix this by not using class names but instead only looking at the actual HTML structure, but like I said it is already hard enough finding the right selector for the search result page
Google’s ReCaptcha
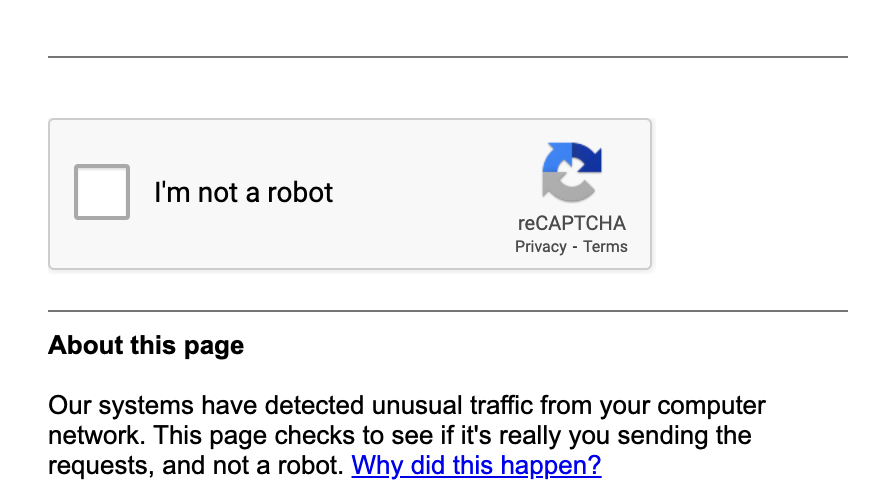
The most important reason why it is so hard to scrape the Google Search Result Page using Python, is Google’s ReCaptcha. ReCaptchas are the nightmare of any scraper and are especially made to make sure that an interaction is performed by a human. There are many guides explaining how you can circumvent a ReCaptcha, but please bear in mind that these things sole purpose are to prevent any bot interaction.
Therefore, I would discourage you to find a way to bypass these ReCaptchas, especially the ones by Google. If you have an easy ReCaptcha that asks you to calculate some numbers, or even the ones that have a blurry picture and you need to find the word inside that image, then yes you might find a way to bypass them. Google’s ReCaptcha, however, is more sophisticated so I would not even go and try it if I was you. I know this sounds demotivating, but believe me, I have already figured this out the hard way (trying different methods).
What is Scaleserp?
Scale SERP, like any other Google Scraper API, is a technology that allows you to easily scrape the Google Search Result Page.

Compared to other SERP APIs, Scale SERP is the most cost-efficient. Also, as I only work on small projects, I am able to use the Free Tier and only pay for the small number of additional queries I am using. You can use this code: SCALESERP_15 to get a 15 percent discount on your first month (sponsored discount)
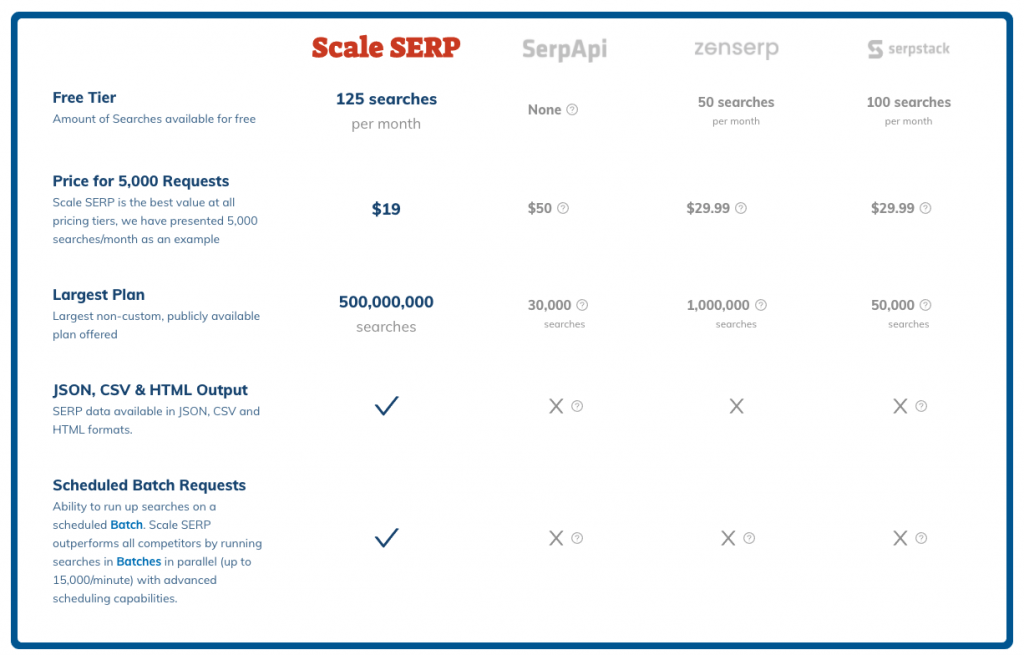
They solve the previously mentioned problems by using the following solutions:
- Vast Proxy Network
- AI Page Parsing
- Captcha Solving
Vast Proxy Network
If you have created scrapers before, you have heard about proxies before. You can consider a proxy to be like a server/computer that sits between you and the website you are visiting. A proxy relays the information you are requesting from a website through itself. In other words, your request first reaches a proxy and then the proxy requests the webpage and sends the information back to you. This prevents Google from knowing that each request is being made from one computer. If you want to learn more about proxies, and how you can create rotating proxies in Python you can check one of my other articles.
AI Page Parsing
As I mentioned before, creating the right selectors for the Google Search Result Page is difficult and these element change over time. Scale SERP solves this by using Artificial Intelligence that creates the right selector for them.
Captcha Solving
The ReCaptcha that I mentioned previously, can be solved using complex Artificial Intelligence. Additionally, they use crowdsourcing, which mean some people are paid to solve these ReCaptchas.
How to Scrape the Google Search Result Page
Step 1. Create an account Scale SERP
Navigate to https://app.scaleserp.com/signup and fill in your name email and password. You can use this code: SCALESERP_15 to get a 15 percent discount on your first month (sponsored discount)
Step 2. Obtain your API Key
Login to Scale SERP by navigating to https://app.scaleserp.com/playground and filling in your credentials. In the top-right corner you should be able to find your API keys.
Step 3. Scrape Google Search Result Page
As we are using an API, we will be using the requests modules in Python. You can check one of my other articles to get a better understanding of how the library works. For now, you only need to know that we are going to do a HTTP GET request to the Scaleserp server. This will give us a response object that we can parse to output the relevant information. In this example, I will show you how you can use the pandas module to create a CSV with all organic results information
import requests
import json
import pandas as pd
query = "How to Scrape Google Search Result Page using Python"
# set up the request parameters
params = {
'api_key': {API_KEY},
'q': query,
'location_auto': True,
'google_domain': 'google.com',
'num': 100,
'hide_base64_images': True,
'output': 'json',
'page': 1
}
# make the http GET request to Scale SERP
result = requests.get('https://api.scaleserp.com/search', params)
result = result.json()
if "organic_results" in result:
result = result["organic_results"]
results.append(result)
df = pd.DataFrame(results)
df.to_csv("results/output.csv")You will need to replace {API Key} with the value you received in step 2. This example using location_auto to automatically get the location based on the google domain. We are using google.com so the location will be the USA. The output will be a JSON object, but we could get CSV and HTML as well. You can check the documentation to see what other parameters you can use. I prefer a JSON object so I can add this to a list, and then export the list as a CSV whenever I have gotten all the results that I wanted.
Step 4 (Optional). Process results
For one of the scrapers I created I was only interested in the title, the link, and the position. I still prefer to output all the fields in step 3, instead of only selecting some fields using the csv_field parameter. This allows me have a raw data file for if I need more information for certain queries. I create a separate script that processes this raw data and gives me an output with the relevant fields.
import pandas as pd
import json
df = pd.read_csv("results/output.csv", index_col=0)
output = []
def transform(x):
if type(x) != float:
x = x.replace(": nan", ": 'NaN'")
y = eval(x)
output.append({ "title": y["title"],
"url": y["link"],
"position": y["position"]}
)
return y
else:
return x
df.applymap(transform)
df = pd.DataFrame(output)
df.to_csv("results/processed.csv")We read the raw data output file from step 3 and the clean it up a little bit before we append it to our new output variable. As mentioned before, we are only interested in title, url, and position. This will be put into a new file called “processed.csv” containing the aforementioned three columns.

I hope you now have a better understanding about how to scrape Google Search Result Page using Python. If you have any questions, do not hesitate to comment below.